What is “Mullins”?
“Mullins” (ML) is the next generation A4 “APU” SoC from AMD (v2 2015) replacing the current A4 “Kaveri” (KV) SoC which was AMD’s major foray into tablets/netbooks replacing the older “Brazos” E-Series APUs. While still at a default 15W TDP, it can be “powered down” for lower TDP where required – similar to what Intel has done with the ULV Core versions
While Kabini was a major update both CPU and GPU vs. Brazos, Mullins is a minor drop-in update adding just a few features while waiting for the next generation to take over:
- Turbo: Where possible within power envelope Mullins can now Turbo to higher clocks.
- Clock: Model replacements (e.g. A4-6000 vs. 5000) are clocked faster.
- Crypto: Random number generator.
- Security: Platform Security Processor (PSP) included in the SoC (ARM based).
In this article we test CPU core performance; please see our other articles on:
Hardware Specifications
We are comparing Mullins with its predecessor (Kabini) as well as its competition from Intel.
| APU Specifications | Atom X7 Z8700 (CherryTrail) | Core M 5Y10 (Broadwell-Y) | A4-5000 (Kabini) | A4-6000? (Mullins) | Comments | |
| Cores (CU) / Threads (SP) | 4C / 4T | 4C / 4T | 2C / 4T | 4C / 4T | We still have 4 cores and 4 threads just like Atom (old and new) – only Core M has 2 cores with HT – we shall see whether this makes a big difference. | |
| Speed (Min / Max / Turbo) | 480-1600-2400 (6x-20x-30x) | 500-800-2000 (5x-8x-20x) | 1000-1500 (10x-15x) | 1000-1800-2400 (10x-18x-24x) | Mullins is clocked a bit higher (1.8GHz vs. 1.5 – 20% faster) but also supports Turbo (up to 2.4GHz – up to 60% faster) which should give it a big advantage over old Kabini. Both Atom and Core M also depend on opportunistic Turbo for most of their performance. As Mullins/Kabini are 15W rated, they should be able to Turbo higher and for longer – at least in theory. | |
| Power (TDP) | 2.4W | 4.5W | 15W | 15W [=] | TDP remains the same at 15W which is a bit disappointing considering the new Atom is 2.4-4W rated, we’re taling between 3-5x (five times) more power! | |
| L1D / L1I Caches | 4x 24kB 6-way / 4x 32kB 8-way | 2x 32kB 8-way / 2x 32kB 8-way | 4x 32kB 8-way / 4x 32kB 2-way | 4x 32kB 8-way / 4x 32kB 2-way | No change in L1 caches which pretty much Atom, comparatively Core M has half the caches. | |
| L2 Caches | 2x 1MB 16-way | 4MB 16-way | 2MB 16-way | 2MB 16-way | No change in L2 cache; here Core M has twice as much cache – same size as a normal i7 ULV. It’s a pity AMD was not able to increase the caches. | |
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets (AVX2, AVX, etc.). Haswell introduces AVX2 which allows 256-bit integer SIMD (AVX only allowed 128-bit) and FMA3 – finally bringing “fused-multiply-add” for Intel CPUs. We are now seeing CPUs getting as wide a GP(GPUs) – not far from AVX3 512-bit in “Phi”.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 8.1 x64, latest AMD and Intel drivers. Turbo / Dynamic Overclocking was enabled on both configurations.
| Native Benchmarks | Atom X7 Z8700 (CherryTrail) | Core M 5Y10 (Broadwell-Y) | A4-5000 (Kabini) | A4-6000? (Mullins) | Comments | |
 |
||||||
 |
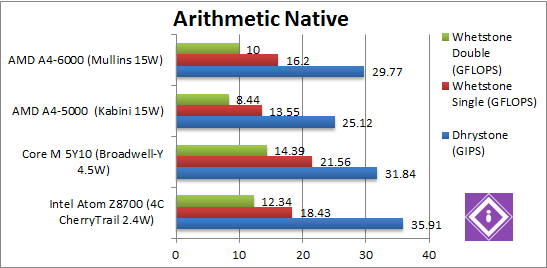
Native Dhrystone (GIPS) | 35.91 SSE4 [+20%] | 31.84 AVX2 | 25.12 SSE4 | 28.77 SSE4 [+18%] | Mullins like Kabini has no AVX2, but is still 18% faster than it (clocked 20% faster), unfortunately the new Atom manages to beat it. Not the best of starts. |
|
Native FP32 (Float) Whetstone (GFLOPS) | 18.43 AVX [+13%] | 21.56 AVX/FMA | 13.55 AVX | 16.2 AVX [+19%] | Mullins has no FMA either, so is again 19% faster than Kabini – it shows the ALU and FPUs are unchanged. Again Atom manages to be faster. |
|
Native FP64 (Double) Whetstone (GFLOPS) | 12.34 AVX [+23%] | 13.49 AVX/FMA | 8.44 AVX | 10 AVX [+18%] | With FP64 we see the same 18% difference – and Atom is still 20% faster. |
| We only see a 18-19% improvement in Mullins – in line with clock speed (+20%) with Turbo not doing much. The new CherryTrail Atom is thus 14-21% faster than it, not something you expect considering the hugely different TDP. Time does not stand still and Mullins is outclassed here. | ||||||
 |
||||||
 |
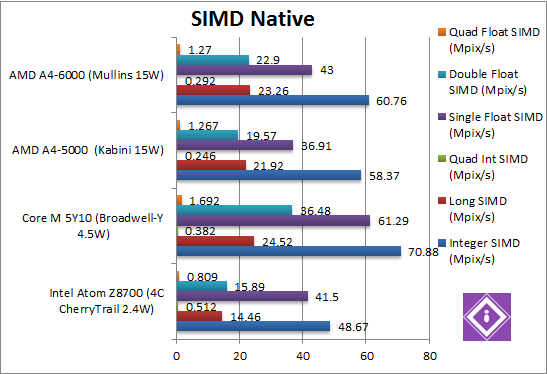
Native Integer (Int32) Multi-Media (Mpix/s) | 48.7 AVX [-20%] | 70.8 AVX2 | 58.37 | 60.76 [+4%] | Without AVX2, Mullins can only manage a paltry 4% improvement over Kabini – the only “silver lining” is that Atom is 20% slower than it – unlike what we saw before. Naturally Core M with AVX2 runs away with it. |
|
Native Long (Int64) Multi-Media (Mpix/s) | 14.5 AVX [-38%] | 24.5 AVX2 | 21.92 AVX | 23.26 AVX [+6%] | With a 64-bit integer workload, the improvement increases to 6%, less than clock difference – but thankfully Atom is much slower (by half) – naturally Core M is the winner. |
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 0.512 [+75%] | 0.382 | 0.246 | 0.292 [+18%] | This is a tough test using Long integers to emulate Int128, but here we see the full 18% improvement over Kabini – but now Atom is a huge 75% faster! |
|
Native Float/FP32 Multi-Media (Mpix/s) | 41.5 AVX [-4%] | 61.3 FMA | 36.91 AVX | 43 AVX [+16%] | In this floating-point AVX/FMA algorithm, Mullins returns to being 16% faster and a whisker faster than Atom (4%). With FMA, Core M is almost 50% faster still. |
|
Native Double/FP64 Multi-Media (Mpix/s) | 15.9 AVX [-31%] | 36.48 FMA | 19.57 AVX | 22.9 AVX [+17%] | Switching to FP64 code, we see a 17% improvement for Mullins which allows it to be 30% faster than Atom. |
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 0.81 AVX [-37%] | 1.69 FMA | 1.27 AVX | 1.27 AVX [=] | In this heavy algorithm using FP64 to mantissa extend FP128, we see no improvement whatsoever – at least Atom is 37% slower; and yes, Core M is faster still. |
| Lack of AVX2/FMA and Turbo that does not seem to engage makes Mullins stuggle to be more than 16-18% faster than Kaveri – but thankfully it can beat its Atom rival sometimes by a good 30% amount. All in all, it does better with SIMD code than we’ve seen elsewhere though without any core changes it is showing its age… | ||||||
 |
||||||
 |
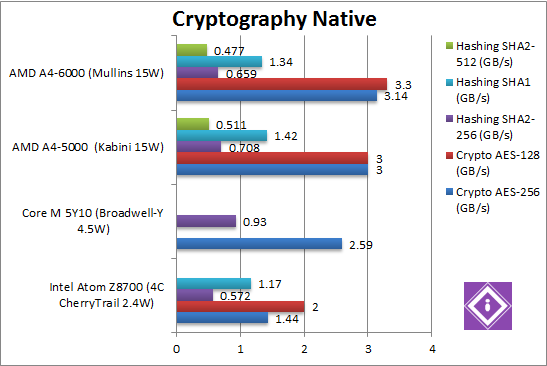
Crypto AES-256 (GB/s) | 1.44 AES HWA [-55%] | 2.59 AES HWA | 3 AES HWA | 3.14 AES HWA [+5%] | All three CPUs support AES HWA – thus it is mainly a matter of memory bandwidth – here Mullins is 5% faster than Kabini and 2x (twice) as fast as Atom, it even overtakes Core M with its dual-channel controller! |
|
Crypto AES-128 (GB/s) | 2 AES HWA [-40%] | ? AES HWA | 3 AES HWA | 3.3 AES HWA [+10%] | What we saw with AES-256 was no fluke: less rounds do make some difference, Mullins is now 10% faster and 65% faster than Atom! |
|
Crypto SHA2-256 (GB/s) | 0.572 AVX [-24%] | 0.93 AVX2 | 0.708 AVX | 0.659 AVX [-7%] | In this tough AVX compute test, Mullins is unexpectedly 7% slower than the old Kabini – but Atom is still slower. But with SHA HWA in the next Atom, AMD will quickly be at a big disadvantage… |
|
Crypto SHA1 (GB/s) | 1.17 AVX [-23%] | ? AVX2 | 1.42 AVX | 1.34 AVX [-6%] | With a less complex algorithm – we still see Mullins 6% slower than Kabini – and again Atom is slower. |
|
Crypto SHA2-512 (GB/s) | ? AVX | ? AVX2 | 0.511 AVX | 0.477 AVX [-7%] | By using 64-bit integers this is pretty much the most complex hashing algorithm and thus tough for all CPUs – and here we see Mullins 7% slower again. |
| Mullins misses both AVX2 and the forthcoming SHA HWA – but manages to extract more memory bandwidth and thus is 5-10% faster than Kabini, and also much faster than Atom. Somehow it manages to be slower with hashing whatever algorithm – but remains much faster than Atom. | ||||||
 |
||||||
 |
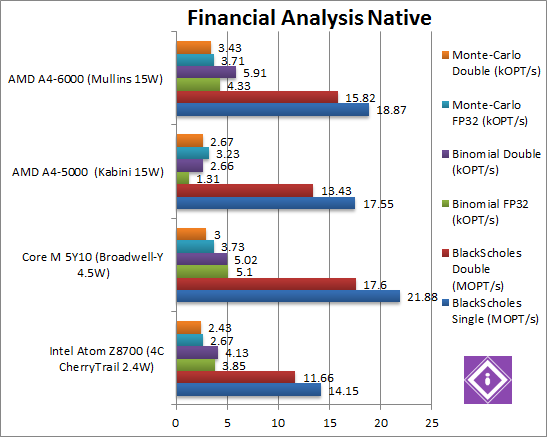
Black-Scholes float/FP32 (MOPT/s) | 14.15 [-26%] | 21.88 | 17.55 | 18.87 [+7%] | In this non-SIMD test we start with a 7% improvement over Kabini, good but less than we expected – but at least faster than Atom. |
|
Black-Scholes double/FP64 (MOPT/s) | 11.66 [-27%] | 17.6 | 13.43 | 15.82 [+18%] | Switching to FP64 code, we see a good 18% improvement – and victory over Atom again. |
|
Binomial float/FP32 (kOPT/s) | 3.85 [-22%] | 5.1 | 1.31 | 4.33 [+3.3x] | Binomial uses thread shared data thus stresses the cache & memory system; Mullins has improved by a huge 3.3x (over three times) – and a great win over Atom (but not Core M). It seems the new memory improvements do help a lot. |
|
Binomial double/FP64 (kOPT/s) | 4.13 [-31%] | 5.02 | 2.66 | 5.91 [+2.2x] | With FP64 code, Mullins is “only” 2.2x (over two times) faster than Kabini – and this again gives it a big win over its Atom competition – as well as over Core M! |
|
Monte-Carlo float/FP32 (kOPT/s) | 2.67 [-29%] | 3.73 | 3.23 | 3.71 [+15%] | Monte-Carlo also uses thread shared data but read-only thus reducing modify pressure on the caches; here Mullins is just 15% faster but it’s enough to tie with Core M and leave Atom in the dust. |
|
Monte-Carlo double/FP64 (kOPT/s) | 2.43 [-30%] | 3.0 | 2.67 | 3.43 [+28%] | Switching to FP64 we see a big 28% improvement – Mullins manages to beat both Atom and Core M by a good measure. |
| Somehow Mullins managed to redeem itself – beating Atom in all tests and even Core M in some of the tests. Running financial tests on a Mullins tablet should work better than on an Atom or Core M one. | ||||||
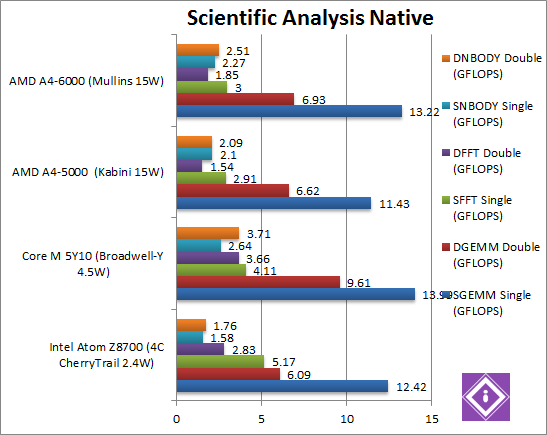 |
||||||
 |
SGEMM (GFLOPS) float/FP32 | 12.42 AVX [-7%] | 13.99 FMA | 11.43 AVX | 13.22 AVX [+16%] | In this tough SIMD algorithm, Mullins sees a good 16% improvement beating Atom and getting within a whisker to Core M – even without FMA. |
|
DGEMM (GFLOPS) double/FP64 | 6.09 AVX [-13%] | 9.61 FMA | 6.62 AVX | 6.93 AVX [+5%] | With FP64 SIMD code, Mullins is just 5% faster – but it’s enough to beat Atom – though not Core M. Still, a good improvement. |
|
SFFT (GFLOPS) float/FP32 | 5.17 AVX [+72%] | 4.11 FMA | 2.91 AVX | 3 AVX [+3%] | FFT also uses SIMD and thus AVX but stresses the memory sub-system more: here Mullins sees only a 3% improvement, not enough to beat Atom which is over 70% faster still. Mullins has its limits. |
|
DFFT (GFLOPS) double/FP64 | 2.83 AVX [+52%] | 3.66 FMA | 1.54 AVX | 1.85 AVX [+20%] | With FP64 code, Mullins improves by a large 20% – but again not enough to beat Atom which is now over 50% faster still. |
|
SNBODY (GFLOPS) float/FP32 | 1.58 AVX [-31%] | 2.64 FMA | 2.1 AVX | 2.27 AVX [+8%] | N-Body simulation is SIMD heavy but many memory accesses to shared data so Mullins is just 8% faster than Kaveri, but enough to beat Atom (by 43%). Unlike FFT, N-Body again agrees with Mullins/Kabini. |
|
DNBODY (GFLOPS) double/FP64 | 1.76 AVX [-30%] | 3.71 FMA | 2.09 AVX | 2.51 AVX [+20%] | With FP64 code Mullins improves again by 20% – but now more than enough to beat Atom (by 42%) – though not enough to beat Core M. |
| With highly optimised SIMD AVX code, Mullins sees a 5-20% improvement – which allows it to beat Atom in most tests – a good result from the rout we saw before. | ||||||
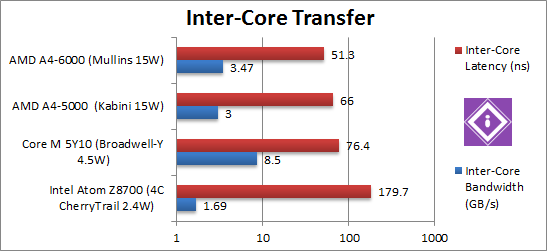 |
||||||
 |
Inter-Core Bandwidth (GB/s) | 1.69 [-52%] | 8.5 | 3.0 | 3.47 [+15%] | With unchanged L1/L2 caches Mullins relies on its higher rated speed – and 15% is a good improvement over Kabini. It’s got 2x (two times) the bandwidth Atom manages to muster – but way below Core M’s which has over 2.4x more still. We see how all these caches perform in the Cache & Memory AMD A4 “Mullins” performance article. |
|
Inter-Core Latency (ns) | 179 [1/3.5x] | 76 | 66 | 31 [-33%] | Latency, however, sees a massive 33% decrease, more than we’d expect – and surprisingly is way lower than Atom (1/3.5x) and even lower than Core M (1/2x). |
While it does not bring any new instruction sets (AVX2, FMA, SHA HWA) and Turbo that does not seem to engage, Mullins’s 20% clock improvement does show and brings a corresponding 5-19% increase in performance over Kabini in most tests.
Against Atom, the scores are all over the place, sometimes Atom (CherryTrail) is 20-70% faster, other times Mullins is 20-55% faster. If they were rated the same TDP-wise that would be a good result – but as Mullins is rated 15W vs. 2.6-4W that’s not really power efficient. Core M is invariably faster than either in just about all tests.
Software VM (.Net/Java) Performance
We are testing arithmetic and vectorised performance of software virtual machines (SVM), i.e. Java and .Net. With operating systems – like Windows 8.x/10 – favouring SVM applications over “legacy” native, the performance of .Net CLR (and Java JVM) has become far more important.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 8.1 x64 SP1, latest Intel drivers. .Net 4.5.x, Java 1.8.x. Turbo / Dynamic Overclocking was enabled on both configurations.
| VM Benchmarks | Atom X7 Z8700 (CherryTrail) | Core M 5Y10 (Broadwell-Y) | A4-5000 (Kabini) | A4-6000? (Mullins) | Comments | |
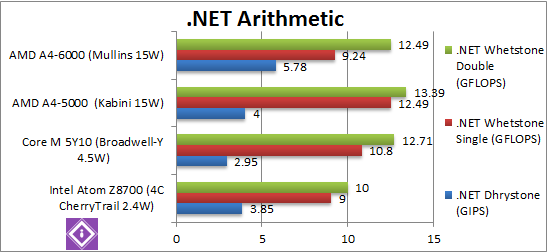 |
||||||
 |
.Net Dhrystone (GIPS) | 3.85 [-33%] | 2.95 | 4.0 | 5.78 [+44%] | .Net CLR performance improves by a huge 44% – a great start and in line to rated clock increase and enough to beat the Atom by 33%. |
|
.Net Whetstone final/FP32 (GFLOPS) | 9 [-3%] | 10.8 | 12.49 | 9.24 [-23%] | Floating-Point CLR performance takes a 23% hit over Kabini – but thankfully just a bit faster than Atom (by just 3%). Something in the new CLR does not agree with it. |
|
.Net Whetstone double/FP64 (GFLOPS) | 10 [-20%] | 12.71 | 13.39 | 12.49 [-7%] | FP64 CLR performance also sees a more modest 7% decrease a performance, but again still 20% faster than Atom. |
| With .Net we see a big variation from 23% lower to 44% higher performance than Kabini, but in all cases higher than Atom (between 3-33%). It is strange to see such a big variance, but the CLR changes may have something to do with it. | ||||||
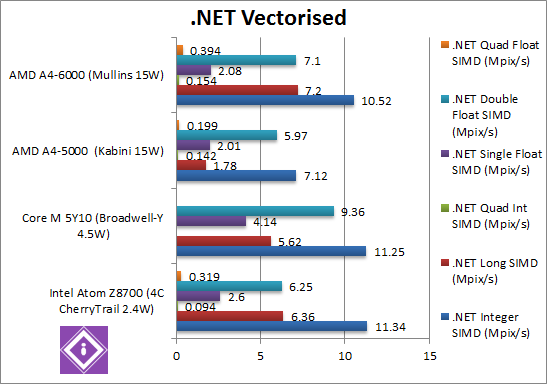 |
||||||
 |
.Net Integer Vectorised/Multi-Media (MPix/s) | 11.34 [+7.8%] | 11.25 | 7.12 | 10.52 [+47%] | Just as we saw with Dhrystone, this integer workload sees a 47% improvement with Mullins – something in the CLR does agree with it – though not as much as Atom which is 8% faster still. |
|
.Net Long Vectorised/Multi-Media (MPix/s) | 6.36 [-12%] | 5.62 | 1.78 | 7.2 [+4.04x] | With 64-bit integer vectorised workload, we see a massive 4x (four times) improvement over Kabini – and 12% faster than Atom. |
|
.Net Float/FP32 Vectorised/Multi-Media (MPix/s) | 2.6 [+25%] | 4.14 | 2.01 | 2.08 [+3%] | Switching to single-precision (FP32) floating-point code, we see only a minor 3% improvement – and here Atom is 25% faster still. |
|
.Net Double/FP64 Vectorised/Multi-Media (MPix/s) | 6.25 [-12%] | 9.36 | 5.97 | 7.1 [+19%] | Switching to FP64 code, Mullins is 19% faster (in line with clock increase) and 12% faster than Atom. While unlikely compute tasks are written in .Net rather than native code, small compute code does benefit. |
| Vectorised .Net improves between 3-47% over Kabini (except the 64-bit integer “fluke”), and thus sometimes faster but sometimes slower than Atom. | ||||||
We see a big variation here – unlike what we saw with native / SIMD code – likely due to CLR changes – but generally welcome. Against Atom we see an even larger variation – faster and slower, but overall competitive.
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
Despite no core changes, Mullins is helped by higher rated clock (and Turbo when that works) – which gives it a good 5-19% performance improvement in most tests over its Kabini predecessor. Any new instruction set support (AVX2, FMA, SHA HWA, etc.) will have to wait for the next model.
Unfortunately, time does not stand still – Atom has seen more core improvements (though no new instruction support either) – which means it is a far tougher competition than what Kabini had to deal with. While competitive performance wise with it – as Mullins is rated at 3-5x the power (15W vs. 2.6-4W) its performance efficiency is low. While it can be “powered down” to hit a lower TDP, performance will naturally suffer – so then it would no longer be competitive with Atom.
Previously, AMD APUs relied on their much more powerful GPUs (see AMD A4 “Mullins” APU GPGPU (Radeon R4) performance) to make up for lower CPU performance and power efficiency – but now the latest Intel APUs (be they Atom or Core) are very much competitive – thus their main advantage has gone.
The only advantage would be cost – assuming that Mullins would be much cheaper than even Atom, though that is difficult to see. Thus there is not much where Mullins would be the top choice.
We’ll have to wait for the next AMD APU model – though, again, time does not stand still – and future Atom/Core M models will bring brand-new goodies (DDR4, new instruction sets, etc.) which may well make even tougher opposition. We shall have to wait and see…